
How to Build Scalable LLM Features: A Step-by-Step Guide
Learn how to effectively build scalable LLM features using distributed systems, microservices, and optimization techniques for improved performance.

Want to build LLM features that scale effortlessly? Here's how you can do it:
- Focus on Scalability: Use distributed systems, containerization (e.g., Docker), and auto-scaling tools to handle growing workloads.
- Optimize Performance: Apply techniques like prompt engineering, retrieval-augmented generation (RAG), and parameter-efficient fine-tuning (PEFT) to improve efficiency.
- Leverage Microservices: Break down applications into smaller units for independent scaling, faster updates, and fault isolation.
- Monitor Key Metrics: Track latency, throughput, and resource usage using tools like Prometheus and Grafana.
- Use Cloud Solutions: Platforms like AWS provide GPU instances, API management, and container orchestration for scalable deployments.
- Incorporate Edge Computing: Reduce latency by processing data closer to users.
Quick Summary of Tools and Techniques:
| Category | Examples | Purpose |
|---|---|---|
| Optimization | Prompt Engineering, RAG, PEFT | Improve accuracy and reduce resource usage. |
| Infrastructure | Docker, AWS Auto Scaling | Ensure seamless scaling and deployment. |
| Monitoring | Prometheus, Grafana | Track system performance and identify issues. |
| Workflow Automation | Kubernetes, Apache Airflow | Streamline processes and ensure reliability. |
Scaling LLMs is all about balancing performance, cost, and reliability. Dive into the guide to learn the practical steps for creating scalable, efficient, and cost-effective LLM features.
LangChain in Production - Microservice Architecture
Scalability in LLM Architecture
Scalability in LLM architecture refers to how well a system can handle growing workloads without sacrificing performance. It plays a critical role in ensuring quick response times, efficient resource use, and a seamless user experience as demand increases.
Key Components of Scalable LLM Systems
A scalable LLM system depends on three main architectural elements that work together to handle growth effectively:
- Distributed Architecture: By dividing workloads across multiple machines, distributed computing allows for parallel processing and minimizes the risk of failure. For instance, distributed training speeds up model training by utilizing several machines simultaneously.
- Containerization: Tools like Docker make deployment consistent, simplify scaling, and standardize dependencies across different environments.
- Auto-scaling Policies: Auto-scaling dynamically adjusts resources based on demand. Services like AWS Application Auto Scaling help manage spikes in usage while cutting costs during quieter periods.
In addition to these components, using a microservices approach can further improve scalability and adaptability.
Microservices in LLM Applications
Microservices architecture divides LLM applications into smaller, independent units that can scale separately. This approach brings several benefits:
| Benefit | Description | Impact on Scalability |
|---|---|---|
| Independent Scaling | Services scale based on individual needs | Ensures efficient resource allocation |
| Isolated Updates | Updates happen without affecting the whole system | Keeps the system continuously available |
| Flexible Development | Teams can work on separate services at once | Speeds up development and feature releases |
| Fault Isolation | Problems in one service don’t disrupt others | Prevents widespread system failures |
Measuring Scalability
To evaluate scalability, focus on metrics like throughput (how many requests are handled per second), latency (response times under different loads), and resource utilization (CPU, memory, and network usage). These metrics help identify bottlenecks and guide decisions for scaling and optimization.
As Klu.ai highlights:
"Optimization requires diagnosing issues, establishing baselines, and selecting targeted solutions" [1]
Edge computing can also play a role by processing data closer to users. This reduces latency and supports real-time performance. For example, edge devices can handle preprocessing tasks, lowering the burden on central servers while keeping the system responsive.
Designing Features for LLM Scalability
Creating scalable features for large language models (LLMs) requires a well-thought-out approach that balances performance and resource use. The goal is to ensure these features can handle growing demands without compromising response times or accuracy.
Distributed Training and Inference
Frameworks like TensorFlow and PyTorch make it possible to distribute processing tasks across multiple devices. They support methods like data, model, and pipeline parallelism to improve training and inference efficiency while reducing the load on individual machines.
Key components of distributed training include:
| Component | Role | Benefits for Scaling |
|---|---|---|
| Data Parallelism | Splits data across devices | Speeds up training by processing batches concurrently |
| Model Parallelism | Spreads model layers across devices | Handles larger models that exceed single-device memory |
| Pipeline Parallelism | Sequences operations across devices | Improves resource use and lowers memory demands |
Once distributed frameworks are in place, the focus shifts to optimizing the models to ensure they perform well as they scale.
Techniques for Model Optimization
Model optimization starts with identifying bottlenecks, establishing performance baselines, and applying targeted strategies like prompt engineering, retrieval-augmented generation (RAG), or fine-tuning. Parameter-efficient fine-tuning (PEFT) is particularly useful for reducing computational costs while keeping accuracy intact, making it a solid choice for teams with limited resources.
But optimization doesn't stop with techniques. The right tools can make a big difference in scaling efforts.
Using Open-Source Tools
Open-source tools simplify LLM development, making it easier to collaborate, optimize, and monitor performance. These tools are especially helpful in tackling scaling challenges like resource management, team collaboration, and performance tracking.
Here are three areas where open-source tools shine:
| Area | Examples | How They Help |
|---|---|---|
| Prompt Engineering | Latitude | Simplifies prompt creation and tracking |
| Model Optimization | TensorFlow Lite | Supports techniques like quantization and pruning |
| Performance Monitoring | MLflow | Tracks experiments and manages model versions |
For teams starting out with LLM features, it's wise to begin with straightforward solutions. Over time, as needs grow, more advanced optimization methods can be added. This step-by-step approach helps manage resources effectively and ensures smoother scaling.
Implementing Scalable LLM Features
Building scalable LLM features involves setting up the right infrastructure, automating workflows, and managing resources intelligently to handle increasing demand. The process revolves around three main aspects: infrastructure setup, workflow automation, and resource scaling.
Setting Up Scalable Infrastructure
Cloud-based solutions are essential for deploying scalable LLM systems. Platforms like AWS offer tools such as ECS for managing containers, API Gateway for creating APIs, and GPU instances for faster inference. These tools form the backbone of scalable deployments.
| Infrastructure Component | Purpose |
|---|---|
| Container Management | Manages clusters for containerized AI workloads |
| API Management | Creates and maintains APIs for seamless integrations |
| Hardware Acceleration | Boosts model performance with GPU-powered processing |
This infrastructure supports distributed training and inference, ensuring systems can grow without sacrificing performance. Together, these components create a robust setup capable of handling increased demand while delivering consistent results.
Orchestrating and Automating Workflows
Workflow automation tools like Apache Airflow and Kubernetes simplify scaling and management. For example, AWS CodePipeline integrates with these tools to streamline deployment, testing, and monitoring. This reduces manual effort and ensures reliability at every stage of development.
By automating workflows, teams can maintain system consistency as LLM features scale. From deployment to monitoring, automation helps create a smooth, reliable operational process with minimal downtime or manual intervention.
Auto-Scaling and Load Balancing
Dynamic resource allocation is critical for managing fluctuating workloads. Tools like AWS Application Auto Scaling adjust resources in real-time based on metrics like CPU usage or network activity. Network Load Balancers further ensure even traffic distribution, avoiding bottlenecks.
These strategies allow organizations to scale their LLM features efficiently, ensuring steady performance while keeping costs under control. Automation combined with robust monitoring tools provides the visibility needed to maintain system stability as demands grow.
Once scalable infrastructure and workflows are in place, the focus shifts to monitoring and fine-tuning performance to ensure the system runs smoothly under practical conditions.
Monitoring and Optimizing LLM Systems
Keeping LLM systems running smoothly at scale means staying on top of performance and making smart adjustments when needed.
Monitoring System Performance
Monitoring helps you keep an eye on key performance metrics in real-time. Tools like Prometheus and Grafana dashboards are great for tracking system health and spotting trends.
| Metric Category | Key Indicators | Monitoring Tools |
|---|---|---|
| System Health & Resource Usage | CPU/GPU Utilization, Memory Usage, Error Rates | Prometheus, AWS CloudWatch |
| Response Performance | Latency, Throughput | Grafana |
Once you're tracking these metrics, the next step is to set performance baselines through benchmarking.
Benchmarking Performance
Benchmarking helps you understand where your system stands and where it needs improvement. It involves measuring current performance, identifying problem areas, and applying targeted fixes.
The process typically includes three stages:
- Assessment and Analysis: Measure current performance and compare it to benchmarks to find bottlenecks.
- Optimization Implementation: Start with quick fixes like prompt engineering, then move to more advanced methods like Retrieval-Augmented Generation (RAG) or fine-tuning as needed.
Once you've optimized the basics, edge computing can take things to the next level for real-time applications.
Using Edge Computing for Lower Latency
Edge computing is key for reducing latency in real-time LLM applications. It works by processing data closer to the user, which speeds things up significantly.
Here’s how to make the most of edge computing:
- Deploy smaller, optimized models at edge locations.
- Spread workloads across multiple edge nodes for better balance.
- Cache frequently used responses locally to cut down on delays.
- Monitor edge node performance separately to ensure smooth operation.
Techniques like Parameter Efficient Fine-Tuning (PEFT), including LoRA, can further improve edge setups. They shrink model sizes while keeping performance intact [3], making it easier to distribute LLM capabilities without compromising quality.
Tools and Practices for LLM Development
Building scalable LLM features that can handle increasing demands requires the right combination of tools and development practices.
Collaborative Development with Latitude
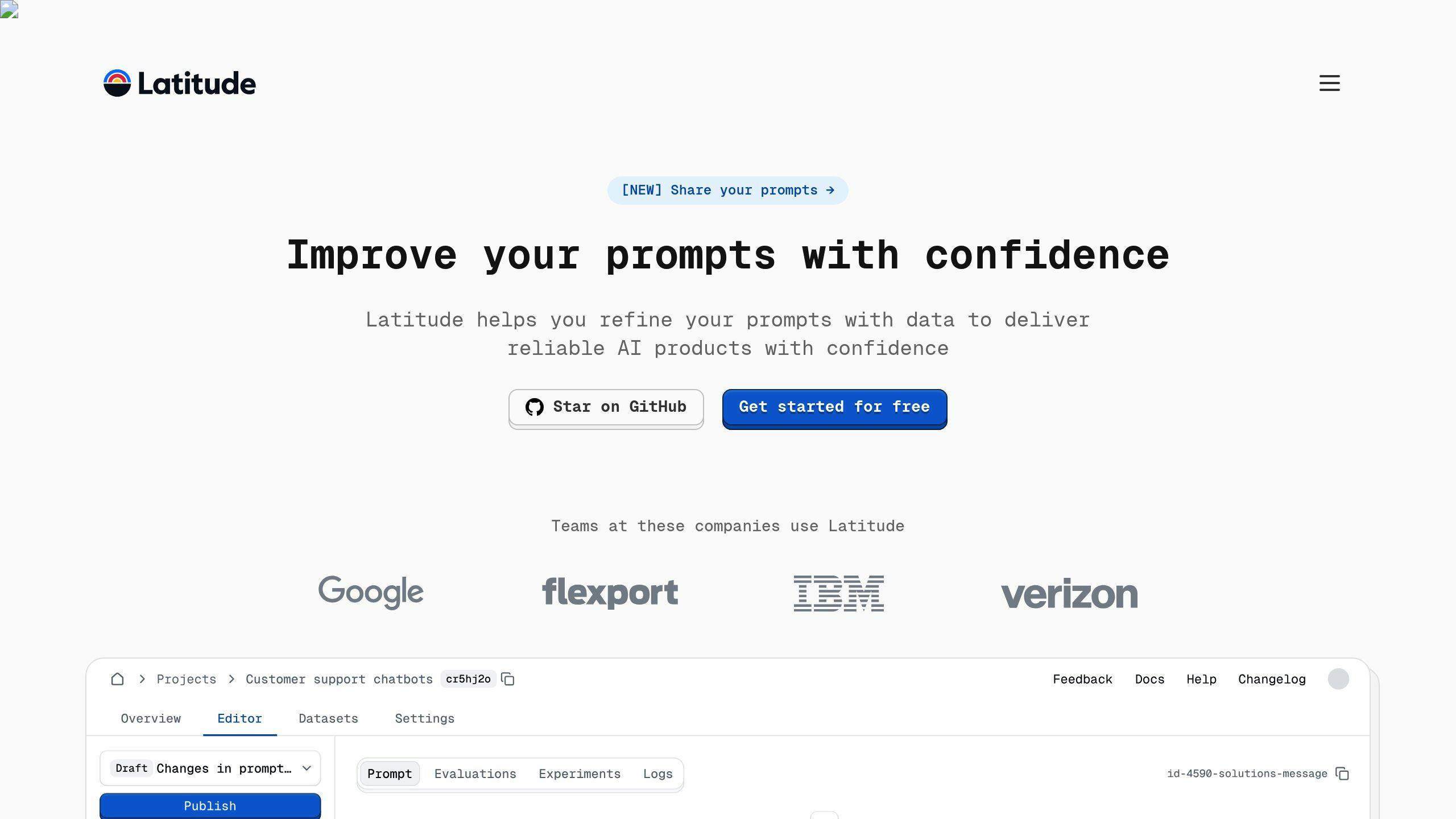
Latitude supports teamwork by offering shared workspaces, version control, and input from domain experts. This setup simplifies prompt engineering and encourages efficient collaboration. Here's how Latitude enhances development workflows:
| Aspect | Benefit | Implementation |
|---|---|---|
| Version Control | Simplifies prompt updates | Track changes and revert if needed |
| Knowledge Sharing | Aligns team understanding | Includes built-in documentation tools |
| Team Workflows | Boosts collaboration | Centralized platform for prompt refinement |
These collaborative tools ensure that teams stay aligned, making the transition from development to production more efficient.
Moving LLM Features to Production
Frameworks like Hugging Face and ONNX are essential for deploying LLM features in production. They provide tools for optimizing models, maintaining performance, and integrating seamlessly with existing infrastructure. Key steps for production deployment include:
- Model optimization and compression: Use ONNX to reduce model size without sacrificing performance.
- Infrastructure integration: Leverage Hugging Face's Transformers library for smooth deployment.
- Automated pipelines: Ensure consistent and error-free updates with automated workflows.
These tools make it easier to deploy LLMs while maintaining performance and reliability.
Cost-Effective Scaling
Scaling LLM features efficiently requires balancing performance and cost. Strategies like AWS Spot Instances, serverless architectures, and auto-scaling can help manage resources while keeping expenses in check:
| Strategy | Cost Impact | Implementation Tips |
|---|---|---|
| Spot Instances | Save 60-90% on compute | Set price caps and enable automated failover |
| Serverless Options | Pay only for usage | Use AWS Lambda or Azure Functions for deployment |
| Auto-scaling | Optimize resource usage | Configure scaling based on traffic patterns |
"Leveraging spot instances for training LLM models can significantly reduce costs while maintaining performance. By specifying maximum price thresholds and implementing proper monitoring, teams can optimize their resource utilization effectively." [1]
Conclusion and Key Points
Building scalable LLM features requires a solid architecture, efficient tools, and well-thought-out implementation. Success comes down to three main pillars:
| Pillar | Core Components | Implementation Focus |
|---|---|---|
| Architecture Design | Distributed Systems, Microservices | Scalability and flexibility in infrastructure |
| Optimization Strategy | Prompt Engineering, RAG, Fine-tuning | Boosting performance and efficiency |
| Operational Excellence | Monitoring, Auto-scaling, Edge Computing | Ensuring reliability and managing costs |
A structured approach to optimization is key for scaling. Techniques like PEFT (Parameter-Efficient Fine-Tuning) reduce computational needs by focusing on limited weight updates during fine-tuning, making it a smart choice for scaling within resource limits. Pairing this with edge computing strategies helps lower latency while maintaining strong performance in LLM applications.
To ensure effective scalability, keep these practices in mind:
- Track key metrics like latency and resource usage to maintain steady performance.
- Leverage auto-scaling and load balancing to manage resources efficiently.
- Adopt serverless architectures and spot instances to reduce operational costs.
Scaling LLM features successfully means balancing technical needs with real-world constraints. By applying these methods, teams can confidently expand their LLM capabilities while keeping systems reliable, efficient, and prepared for increasing demands.
FAQs
How to optimise for LLMs?
Optimizing large language models (LLMs) involves fine-tuning their performance while keeping resource usage in check. Here are some key strategies:
- Prompt Engineering: Experiment with prompts to refine responses through trial and error.
- RAG (Retrieval-Augmented Generation): Integrate domain-specific knowledge dynamically to enhance relevance.
- Fine-tuning: Adjust the model to perform specific tasks more consistently.
These methods, covered in detail under "Techniques for Model Optimization", lay the groundwork for effective LLM deployment. Starting with prompt engineering is a smart move - it helps set benchmarks and improves output quality without heavy resource use [1].
For advanced optimization, consider these techniques:
- Quantization: Lower the model's precision to save resources while keeping accuracy intact.
- Tensor Parallelism: Distribute tensor computations across multiple processors to boost efficiency.
- PEFT (Parameter-Efficient Fine-Tuning): Update only select model weights during fine-tuning, cutting computation needs while maintaining performance [3].
Using specialized hardware like GPUs or TPUs can speed up these processes, particularly for tasks like tensor parallelism. When your application requires real-time, context-specific information, RAG is an excellent tool for injecting relevant knowledge [2].