
How I keep my ExpressJS & React apps fast with server-side caching
In this tutorial, you’ll learn how to implement server-side caching to ensure your app stays fast as you scale. We’ll be using ExpressJS for the API server, and React for our frontend.

TL;DR
In this tutorial, you’ll learn how to implement server-side caching to ensure your app stays fast as you scale. We’ll be using ExpressJS for the API server, and React for our frontend.

Latitude - the open-source framework for embedded analytics
Just a quick background about us. Latitude is a free open-source framework for embedded analytics. We let you create API endpoints on top of your database or warehouse using just SQL, and embed interactive visualizations natively in your favorite frontend framework or through an iframe.
It’d mean a lot if you could give us a star! It will help me to make more articles every week: https://github.com/latitude-dev/latitude
Intro
Working with large data sources can lead to several problems, especially when developing a production-ready project. Sometimes, running queries over the entire dataset can be a very expensive procedure, often leading to poor performance, slow responses, or rate-limiting requests. To mitigate these issues, implementing a server-side cache can be a highly effective solution.
Let’s explore the concept of server-side caching, how it works, how to build one ourselves, and why it is a crucial component in enhancing the efficiency of applications dealing with large volumes of data.
To really understand this issue, let’s build a project! For this example, we are going to create a simple web app that requests information about Pokémon to a server and displays them to the user. Then, we’ll improve the server performance implementing a cache step-by-step.
Project setup
First, let’s create the project environment for the application we will be working on. For this example, we will be using ExpressJS for the API server, and ReactJS as our frontend app.
Create a directory for this project anywhere in your machine, and inside we will add a directory for each our client and server:
mkdir server-cache
cd server-cache
mkdir client server
Server setup
Navigate to the server folder we just created, and start by configuring a npm environment:
cd server
npm init -y
Now, install Express, Nodemon and CORS
npm install express nodemon cors
ExpressJS is a light and fast framework aimed for building web applications in NodeJS. Nodemon is a tool that reloads your web application automatically every time you modify a file, and CORS is a library that allows your server app to communicate with apps on different domains.
Now let’s create our main executable file for our app. Create a file called index.js inside the server directory, and paste this code inside:
const express = require("express");
const cors = require("cors");
const app = express();
const PORT = 4000;
app.use(express.urlencoded({ extended: true }));
app.use(express.json());
app.use(cors());
async function fetchDataFromSource(id) {
// Fetch Pokemon data
const pokemonData = await new Promise((resolve, reject) => {
fetch(`https://pokeapi.co/api/v2/pokemon/${id}`)
.then((response) => response.json())
.then(resolve)
.catch(reject)
})
// Fetch data from each ability
pokemonData.abilities = await Promise.all(
pokemonData.abilities.map(async (abilityData) => (
new Promise((resolve, reject) => {
fetch(abilityData.ability.url)
.then((response) => response.json())
.then(resolve)
.catch(reject)
})
))
)
// Simulate a slow server
await new Promise((resolve) => setTimeout(resolve, 2000));
return pokemonData;
}
app.get("/api/:id", async (req, res) => {
try {
const id = req.params.id;
const result = await fetchDataFromSource(id);
res.json(result);
} catch (error) {
res.status(500).json({ error: error.message });
}
});
app.listen(PORT, () => {
console.log(`Server listening on <http://localhost>:${PORT}`);
});
This code snippet opens a server in your machine on the port 4000, and exposes an entry-point on /api/<id> that returns information about a Pokémon.
To obtain this data, the server will run the function fetchDataFromSource. This function is what takes care of fetching the data from the source. Depending on the project, this could mean running a query over a database, searching for an entry in a file, or any other way of getting the information we requested. In our case, this function sends several requests to the public PokeApi API to gather all of the information for a Pokémon and each of its abilities. Although this API is actually pretty fast, the snippet function adds a manual timeout to simulate a slow server response.
Finally, modify your package.json file to add a “start” command to be able to start the server, like this:
{
... // Keep the rest of the file contents
"scripts": {
"start": "nodemon index.js"
},
...
}
Now, you can start your server running the start command:
npm run start
With the server started, you can already test it out by opening your browser and navigating to http://localhost:4000/api/6, where you should now see a long JSON with the response information.
Client setup
In a different terminal, navigate to the client folder, where we will create the ReactJS app.
cd client
npx create-react-app .
We will also install RadixUI to have access to a library of pre-made UI components.
npm install @radix-ui/themes @radix-ui/react-icons
Now let’s configure this new React app to use RadixUI, as it’s explained in their documentation. Just modify the src/index.js file to look like this:
import React from 'react';
import ReactDOM from 'react-dom/client';
import './index.css';
import App from './App';
import '@radix-ui/themes/styles.css';
import { Theme } from '@radix-ui/themes';
const root = ReactDOM.createRoot(document.getElementById('root'));
root.render(
<React.StrictMode>
<Theme>
<App />
</Theme>
</React.StrictMode>
);
Now that we have the UI library setup, we can create a component that displays information based on a Pokémon data. To do this, create a PokemonCard.js file inside the src folder, and paste the following code:
import { Badge, Card, Flex, Kbd, Strong, Text } from "@radix-ui/themes";
export default function PokemonCard({ data }) {
return (
<Card style={{ backgroundColor: "#656565" }}>
<Flex direction="column" gap="2">
<Flex direction="row" justify="between">
<Text style={{textTransform: "capitalize"}}>
<Strong>{data.name}</Strong>
</Text>
<Kbd>{data.id}</Kbd>
</Flex>
<img
src={data.sprites?.front_default}
alt={data.name}
style={{
display: "block",
objectFit: "contain",
width: "100%",
height: 140,
backgroundColor: "#ffffff",
}}
/>
<Flex direction="row" gap="1">
{data.types.slice(0, 4).map((typeData) => (
<Badge>{typeData.type.name}</Badge>
))}
</Flex>
{data.abilities.slice(0, 4).map((abilityData) => (
<Flex direction="column" gap="1">
<Text size="2">
<Strong>{abilityData.names.find((name) => name.language.name === "en").name}</Strong>
</Text>
<Text size="1">{abilityData.effect_entries.find((entry) => entry.language.name === "en")?.short_effect ?? "No description"}</Text>
</Flex>
))}
</Flex>
</Card>
);
}
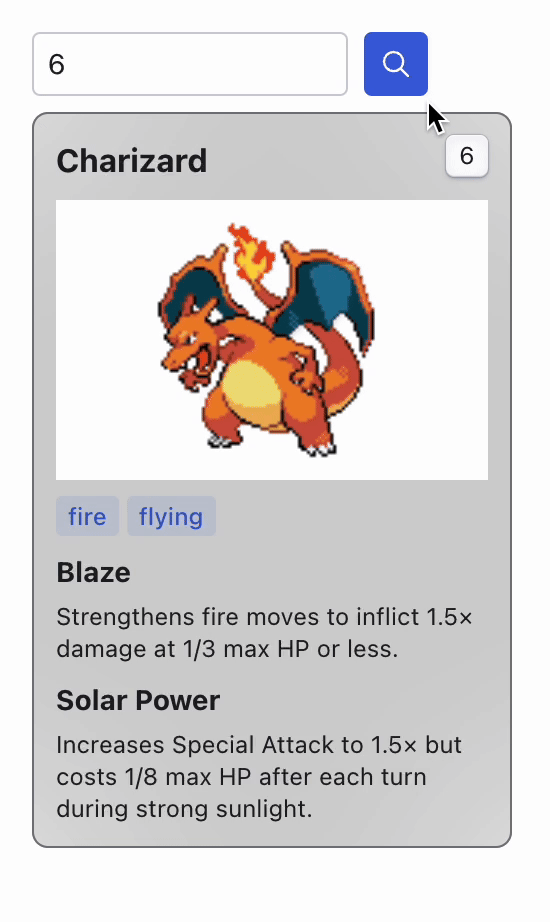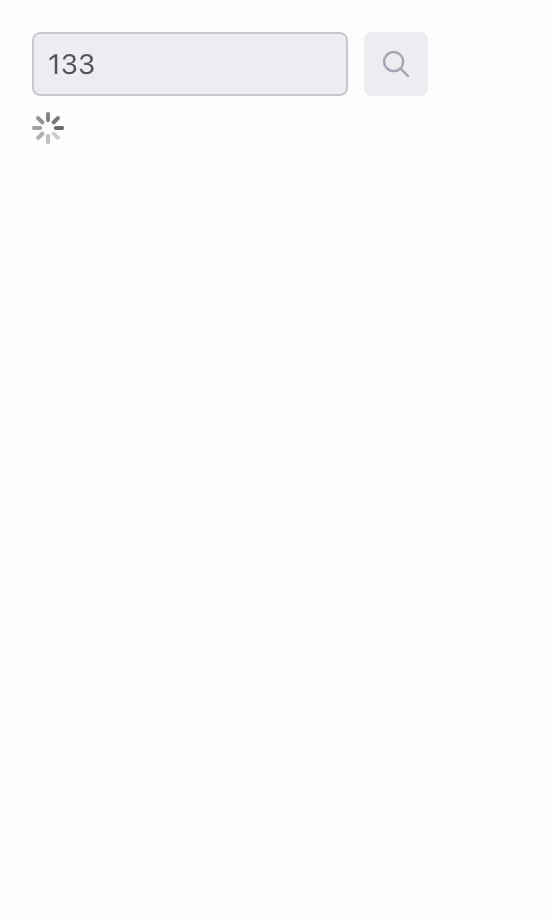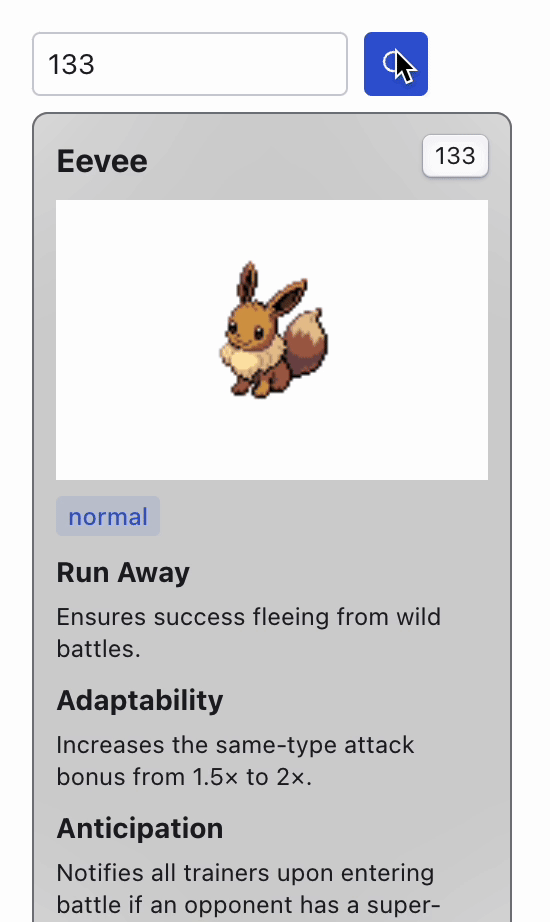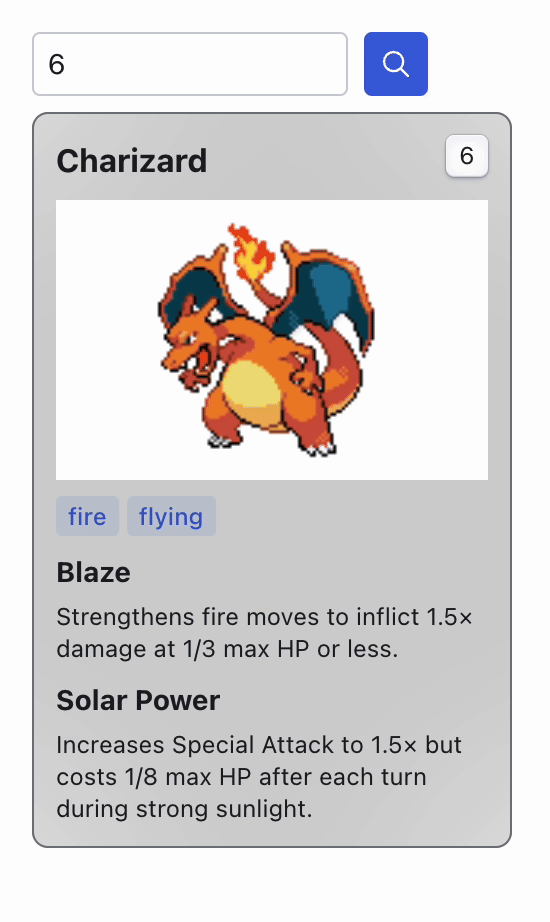
This code defines a component called PokemonCard, that receives the data from a Pokémon as an input and displays some of its information.
Finally, we need to add a way for the user to select the ID of the Pokémon it wants to see, and to send a request to the server to gather this information. To do that, change the content of the src/App.js file to this:
import { Flex, Box, TextField, IconButton, Spinner, Callout } from "@radix-ui/themes";
import { MagnifyingGlassIcon } from "@radix-ui/react-icons";
import { useEffect, useState } from "react";
import PokemonCard from "./PokemonCard";
function App() {
const [pokemonId, setPokemonId] = useState(6);
const [data, setData] = useState(null);
const [isLoading, setIsLoading] = useState(false);
const [error, setError] = useState(null);
function onSubmit() {
if (isLoading) return;
setIsLoading(true);
setData(null);
setError(null);
fetch(`http://localhost:4000/api/${pokemonId}`)
.then(async (response) => {
const data = await response.json();
if (response.ok) setData(data)
else throw new Error(data.error)
})
.catch((error) => setError(error))
.finally(() => setIsLoading(false));
}
useEffect(onSubmit, []);
return (
<Box maxWidth="240px" m="4">
<Flex direction="column" gap="2">
<Flex direction="row" gap="2">
<TextField.Root
placeholder="Pokemon ID"
type="number"
value={pokemonId}
onChange={(e) => setPokemonId(e.target.value)}
disabled={isLoading}
onKeyPress={(e) => {
if (e.key === "Enter") {
onSubmit();
}
}}
/>
<IconButton onClick={onSubmit} disabled={isLoading}>
<MagnifyingGlassIcon width="18" height="18" />
</IconButton>
</Flex>
{isLoading && <Spinner />}
{data && <PokemonCard data={data} />}
{error && (
<Callout.Root color="red">
<Callout.Text>{error.message}</Callout.Text>
</Callout.Root>
)}
</Flex>
</Box>
);
}
export default App;
This code snippet defines our main App component. Here, we display a TextField input that we use to select an ID. Then, when the user clicks on the button, it runs the onSubmit function, that sends a request to our API server and saves the response data to the data variable. Finally, when this variable is not null, it imports and displays our previously created PokemonCard component with this data.
Let’s try it out! Run the client with the following command:
npm run start
Remember to have both server and client running at the same time!
When you launch the app, a card displaying information about a Pokémon appears. To view details about a different Pokémon, simply change the ID in the selector above and click the search button. This action sends a request to the server, which then updates the display with the new Pokémon's information.
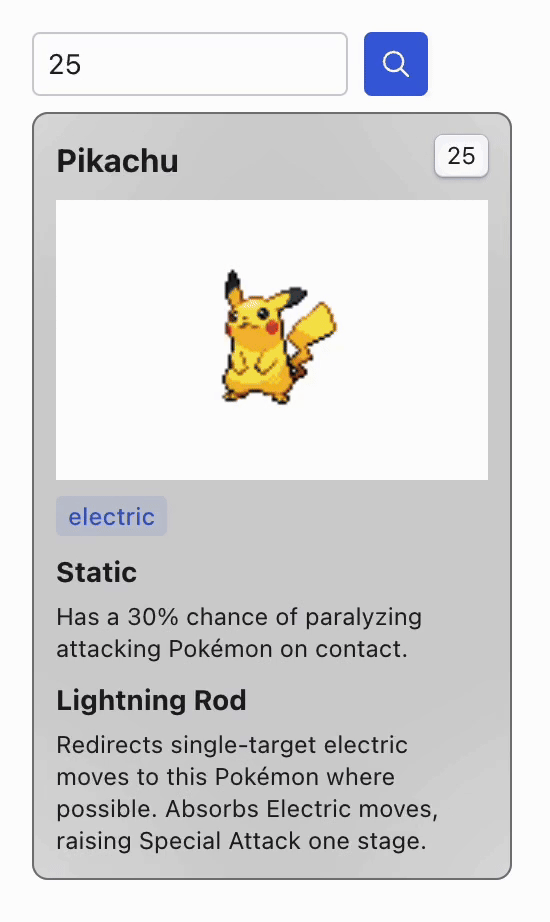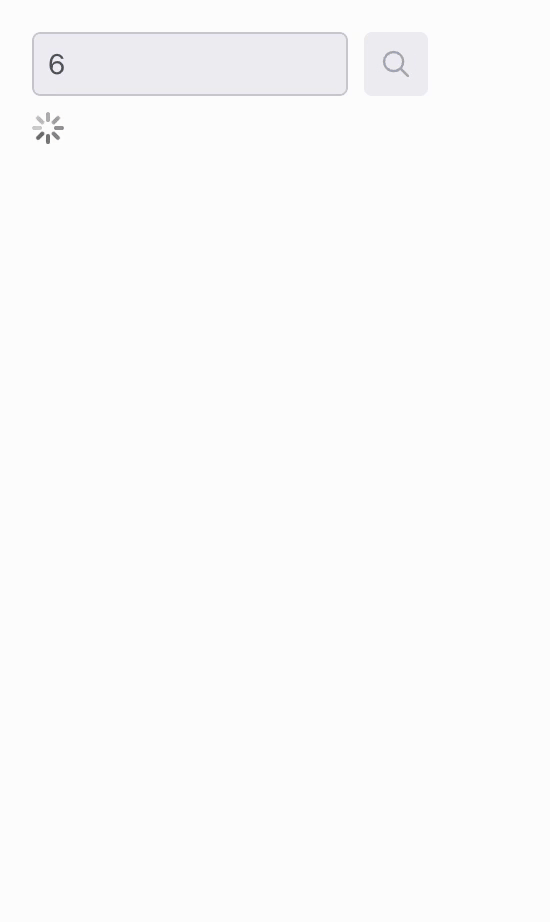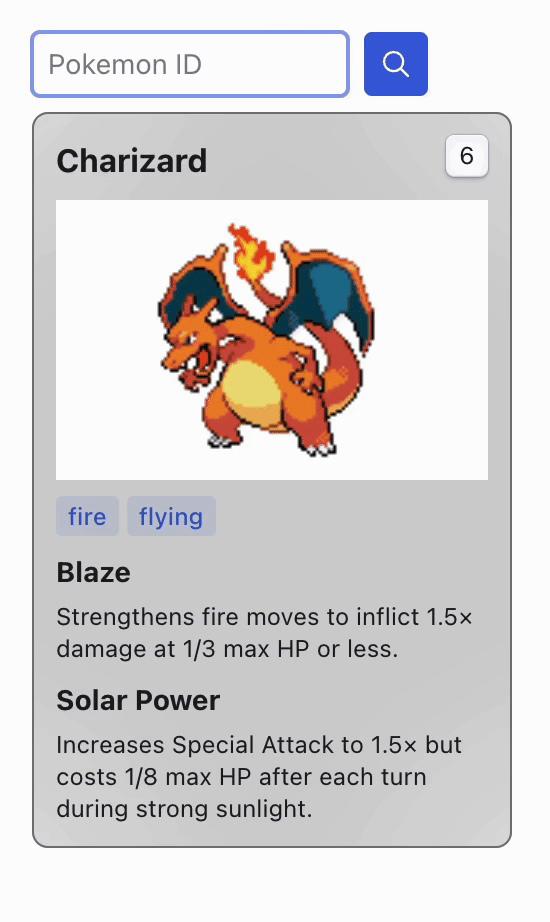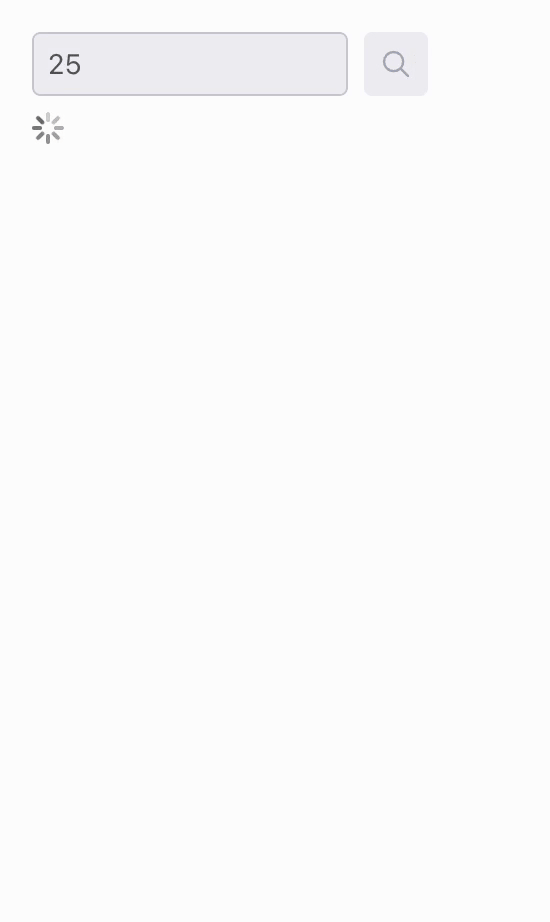
You may notice that retrieving information for different Pokémon takes a long time, even for IDs that have been previously searched. Although we are simulating this bad response performance for this example, it is an actual problem that is incredibly common when dealing with large data sources.
Now, without changing the time it takes for the actual data source to respond, how can we improve the performance of our server?
What’s a server-side cache
A cache is a temporary storage area where frequently accessed data can be stored for rapid access. Implementing a cache on the server side allows us to store results of previous queries so that future requests can be served faster, bypassing the need to retrieve data from the original data source for every single time.
There are several caching strategies, and choosing the right one depends on your specific requirements. Let’s explore some of the most common cache solutions in detail.
In-memory cache
An in-memory cache stores data directly within the RAM of the server, providing the quickest access times because there are no intermediate layers like disk I/O to slow down the data retrieval process. This can be done as simply as storing the data into an object in the server runtime memory.
This type of cache is particularly useful for relatively small and manageable dataset. Data stored in RAM is volatile, meaning it will be lost if the server is restarted or crashes, which might require reloading or reconstructing the cache periodically. Also, storing too much data in RAM can be expensive, so this method is not suitable for medium or larger datasets.
File-based cache
File-based caching involves storing cache data as files on a server's disk. This method is more persistent than in-memory caching, as the data remains intact even after a server restart.
It is generally used for applications where data does not change frequently and does not require the fastest possible retrieval times. File-based caches are easier to implement and manage compared to more complex caching systems and are suitable for small to medium-sized applications that need a straightforward caching solution without the overhead of additional infrastructure.
Cloud Storage Caching
Cloud storage services like Amazon S3 can also be used for caching, particularly when dealing with large datasets that need to be durable and accessible across a distributed system. This method offloads the storage to a scalable, managed infrastructure, reducing the load on local servers.
Having to fetch large quantities of data from a cloud storage can introduce some latency, but that still may improve performance for massive datasets where querying the original data source can be way more expensive.
Distributed Cache
A distributed cache spreads its data across multiple servers. This means that instead of one single cache on one server, the cache is shared over a network of machines, which helps handle more data and serve more users simultaneously. They are especially useful for applications that need quick data access and can handle lots of requests for large datasets, such as online gaming platforms, e-commerce websites, and financial applications.
Redis is a popular choice for a distributed cache. It is fast and supports a variety of data types like strings, lists, and hash maps, making it versatile for different needs. The ability to perform quick, real-time operations on data stored in the cache makes Redis an excellent option for scenarios where both speed and data integrity are crucial.
Building a cache system
For this example we are going to be implementing a file-based cache on our project.
Let’s start by creating a getResult function that takes care of retrieving the result from either the source or the cache. Since currently we don’t have any cache implemented, we will just fetch the data and then return it.
async function getResult(id) {
const result = await fetchDataFromSource(id);
return result;
}
app.get("/api/:id", async (req, res) => {
try {
const id = req.params.id;
const result = await getResult(id);
res.json(result);
} catch (error) {
res.status(500).json({ error: error.message });
}
});
The server will still do the exact same, but we can now start building the cache implementation inside this new function.
Let’s start with the basics. Every time we retrieve data from the source, we must save it somewhere. For this purpose, we'll use a directory named .cache, which is conventionally hidden from user view because it starts with a dot (.). The data will be stored in a file format that ensures it can be accurately read in the future. Given that our data is a JSON response, we will use .json files, storing the data as a plain string.
The file naming convention is crucial for efficiently retrieving cached data. If the response varies based on certain request parameters, we need a reliable method to identify the relevant file for each data fetch. When the request is defined by multiple attributes, a good approach would be hashing these attributes to generate a unique key. This key serves as the file name and ensures that identical requests map to the same cached file. In our case, the request is uniquely identified by a single id attribute, so we can directly use it as the filename. This simplifies the caching system while maintaining quick data access.
const fs = require("fs"); // Add this line to the top of the file
async function getResult(id) {
const result = await fetchDataFromSource(id);
// Create the .cache folder if it doesn't exist
if (!fs.existsSync(".cache")) fs.mkdirSync(".cache");
// Save the data into a json file as a string
const filename = `.cache/${id}.json`;
const resultAsString = JSON.stringify(result)
fs.writeFileSync(filename, resultAsString);
return result;
}
In this code snippet, we first ensure that the .cache directory exists; if it does not, the directory is automatically created before we proceed with saving the file.
Go ahead and test it now. When you fetch information about new Pokémon, you will notice that a .cache folder has been created within your server directory. This folder now contains .json files for each Pokémon ID you've requested. However, you will still observe poor performance because even though the files are being created, the data is still being fetched from the source every single time.
This is where the real optimization begins. Before fetching data from the source, we first check the .cache folder for a cached file corresponding to the requested data. Not every piece of data will be cached initially, but when it is available, we can directly serve this cached data and skip the need to fetch from the source entirely! Let’s implement this:
async function getResult(id) {
const filename = `.cache/${id}.json`;
// If the cached file exists, read it and return the cached data
if (fs.existsSync(filename)) {
const resultAsString = fs.readFileSync(filename);
const result = JSON.parse(resultAsString);
return result;
}
// Else, fetch the data from the source and save it to the cache
const result = await fetchDataFromSource(id);
if (!fs.existsSync(".cache")) fs.mkdirSync(".cache");
const resultAsString = JSON.stringify(result);
fs.writeFileSync(filename, resultAsString);
return result;
}
Now, give your app another test. When you request data for a Pokémon that hasn't been looked up before, the loading time will be the same as initially. However, for any future requests for the same Pokémon, the response time will be almost instant! This demonstrates the power and effectiveness of adding caching to your application.
We have greatly improved the performance of our app. As more data is requested over time, the cache will accumulate more results. However, this leads to one of the primary challenges of caching: data variability. What happens if the original data changes? Suddenly, our cache holds information that will no longer be up to date.
Cache invalidation
Cache invalidation is the process by which entries in the cache are marked as outdated and thus ready to be updated or removed. This is crucial to maintain the integrity and relevance of the data being served to the users, ensuring that the cached data remains accurate and up to date with the source.
One way you can currently invalidate the cached data is by simply removing the cache folder. This will force the app to refetch the data from the original source, updating the cache in the process. Although this works as a manual workaround, it is impractical for scalable applications. Let’s explore some other options to implement different ways of cache invalidation:
- Requested invalidation involves adding a way to explicitly request to the server to refetch the data from the source instead of getting it from the cache. This can be implemented as an additional attribute on the API request, a new header, or even as a different endpoint.
- Time-based Expiration, or TTL (Time to Live) lets you assign an expiration date to the cached data based on your app’s requirements. This way, returning the cached data not only requires the data being available in the cache, but also that it is recent enough to not be considered expired. This strategy is particularly useful when data updates occur at known intervals or when brief periods of stale data are acceptable. It simplifies cache management by automating the invalidation process, reducing the need for manual intervention.
- Event-based cache invalidation, where the cache is updated or invalidated in response to specific events, such as updates to the original data source. This method ensures that the cache always reflects the most current data, but it requires a mechanism to detect changes and trigger cache updates.
Different caching strategies may suit different projects based on their specific use cases and requirements. For our project, we will implement Time-based Expiration on our cache entries to ensure that we are displaying up-to-date information in our app.
The first step involves determining the lifespan of our cached data before it is considered outdated. In the context of our project, although it is not that common, data can be updated by the community at any time. While do not know the exact rate at which this happen, setting a time-to-live (TTL) of 1 day is a reasonable compromise. This duration strikes a balance, allowing us to maintain reasonably current data without excessive refetching.
There are several different ways to identify if a cache entry is old enough. We could add the creation timestamp in the filename after the id, or add it as a property inside the JSON content itself, for example. In our case, we are going to take advantage of the file system, since it already contains information about when a file was created.
function isValidCacheEntry(filename) {
const TTL = 1000 * 60 * 60 * 24; // 1 day in milliseconds
// If the file doesn't exist, it's not valid
if (!fs.existsSync(filename)) {
return false;
}
// If the file exists but is older than the TTL, it's not valid
const fileAge = Date.now() - fs.statSync(filename).mtimeMs;
if (fileAge > TTL) {
return false;
}
// Otherwise, it's valid
return true;
}
This code snippet defines an isValidCacheEntry function that takes a filename as an input, and checks if it is a valid cache entry. It starts by verifying the existence of the file. If the file does not exist, the function immediately returns false. For existing files, it calculates the age of the file and compares it to the predefined TTL (1 day) and returns true or false depending on if the file is older than this variable.
Now, just replace the conditional statement in the getResult function where we just check if the file exists, with the new more complex function:
async function getResult(id) {
const filename = `.cache/${id}.json`;
if (isValidCacheEntry(filename)) { // <-- Replaced with new check
const resultAsString = fs.readFileSync(filename);
const result = JSON.parse(resultAsString);
return result;
}
const result = await fetchDataFromSource(id);
if (!fs.existsSync(".cache")) fs.mkdirSync(".cache");
const resultAsString = JSON.stringify(result);
fs.writeFileSync(filename, resultAsString);
return result;
}
In our case, we don’t need to remove the cached file when they have expired, because it will automatically fetch the results from the source and replace it with a new file.
Now, the first time we look for a Pokémon in our app will take time to load, but it will be instant for the rest of the day. However, on the following day, requesting the same Pokémon will again take longer, as the cache entry from the previous day will have expired and needs to be updated. This ensures that the information provided is up-to-date, balancing performance with data accuracy.
Conclusion
In this article, we’ve explored how server-side caching can significantly enhance the performance of web applications, especially those dealing with large or frequently accessed datasets. It can take a huge role in any production-ready server performance.
By building a simple web application, we demonstrated the practical steps involved in setting up a server-side cache, from project setup to implementation of caching strategies. Now, you can try to improve it even further by implementing more cache invalidation methods as explained, or trying to use a whole different strategy for the cache system!
Building robust, high-quality projects can be really demanding and time consuming. Bringing your idea to a production-ready state forces you to focus not only on the fun part, but building a solid infrastructure to work on too. Tools like Latitude provide a comprehensive solution, handling many complexities of system architecture while still giving developers full control over their projects.
You can access the source code of this tutorial here: https://github.com/latitude-dev/server-side-cache-tutorial
Thanks for reading!
Could you help me out?
If you feel like this article helped you understand how to build a server-side cache, I would be happy if you could give us a star! ❤️
https://github.com/latitude-dev/latitude
