
5 Ways to Optimize LLM Prompts for Production Environments
Learn effective strategies to optimize LLM prompts for production environments, enhancing accuracy, scalability, and performance.

Optimizing prompts for large language models (LLMs) ensures faster, more accurate, and scalable results in production. Here’s how you can improve LLM prompt performance:
- Use Clear and Focused Prompts: Be specific, define the scope, and structure inputs/outputs clearly (e.g., JSON or Markdown formats).
- Leverage Templates: Standardize reusable prompt templates for consistency and efficiency.
- Scale Effectively: Break down complex tasks into smaller steps and adjust prompts regularly based on performance.
- Apply Advanced Techniques: Use methods like few-shot prompting (examples in prompts) and chain-of-thought reasoning (step-by-step logic) for better accuracy.
- Manage Prompts Systematically: Centralize prompt libraries, monitor performance metrics, and refine prompts based on feedback.
Quick Overview
| Optimization Area | Key Strategy | Impact |
|---|---|---|
| Clear Prompts | Specific language, structured formats | Consistent and accurate outputs |
| Templates | Reusable, standardized templates | Scalable and reliable results |
| Scalability | Task decomposition, regular updates | Efficient performance at scale |
| Advanced Techniques | Few-shot and chain-of-thought prompting | Improved reasoning and accuracy |
| Prompt Management | Centralized repositories, performance tracking | Streamlined operations |
These strategies help you create reliable, efficient prompts that adapt to production needs while maintaining high-quality outputs.
Related video from YouTube
1. Creating Clear and Focused Prompts
Crafting precise and well-structured prompts is key to getting the most out of LLMs in production settings. Clear prompts not only improve accuracy but also reduce processing time and resource usage.
1.1 Using Specific Language
Choosing the right words can guide LLMs to deliver accurate and relevant responses. Here's a quick guide:
| Do | Don't |
|---|---|
| Use precise keywords | Use vague terms (e.g., "it", "this") |
| Specify the desired output format | Leave format requirements undefined |
| Provide necessary context | Assume the model understands the context |
| Clearly define the scope | Make open-ended requests |
1.2 Implementing Structured Formats
Structured formats help models understand input-output requirements more effectively. They ensure consistent and predictable responses. Commonly used formats include:
| Format | When to Use |
|---|---|
| JSON | For easy parsing and data extraction |
| XML | When dealing with nested or hierarchical data |
| Markdown | For generating human-readable text formats |
1.3 Testing with Diverse Scenarios
Precise language and structured formats simplify testing across a variety of conditions. Recent data shows that even smaller models, like Llama-70B, can perform on par with larger models like GPT-4 when prompts are optimized correctly. For example, tests revealed only a 0.5% difference in performance (91.9% vs 92.4%) [1].
To ensure reliability, test prompts under different scenarios, including edge cases. Use real-world feedback to refine them further. Iterative testing and adjustments are critical for dependable results.
Once your prompts are clear and well-tested, the next step is to ensure consistency across deployments by utilizing templates.
2. Using Templates for Consistency
Standardizing prompt templates plays a key role in ensuring reliable performance of large language models (LLMs) in production. Templates help streamline workflows and standardize outputs for similar tasks, making it easier to scale and manage deployments effectively.
2.1 Creating Reusable Templates
To get started, identify recurring task patterns and design templates that can be reused. Below are the main components and metrics to consider when building and managing templates:
| Component/Metric | Purpose | Example/What to Monitor |
|---|---|---|
| Task Definition | Clearly defines the goal | {task}: Generate a {output_type} for {input} |
| Context Block | Offers necessary background | Given the following {context_type}: {context} |
| Output Format | Sets the structure for responses | Respond using this format: {format_specification} |
| Accuracy | Ensures outputs meet requirements | Monitor correctness of responses |
| Processing Time | Tracks speed of execution | Measure response generation time |
| Error Rates | Flags failures or issues | Monitor invalid or incomplete outputs |
When creating templates, focus on building components that are easy to customize while keeping the core structure intact. Tools like PromptL Templating Language include built-in features for template management, enabling teams to standardize prompts efficiently across various tasks.
2.2 Refining Templates with Feedback
Improving templates is an ongoing process. Regularly analyze performance metrics, review failures, and incorporate user feedback to refine templates. This iterative approach helps maintain consistency and ensures better results over time.
Once your templates are standardized, you’ll be ready to handle higher demands without compromising on performance or reliability.
3. Optimizing Prompts for Scalability
Effectively scaling LLM prompts in production requires fine-tuning to handle varying workloads while maintaining performance. Recent deployments highlight that optimized prompts can cut computational costs without sacrificing accuracy.
3.1 Breaking Down Complex Tasks
Large language models (LLMs) can struggle with overly complex tasks. Splitting these into smaller, more manageable steps - known as task decomposition - can improve both accuracy and efficiency.
Here's a quick comparison of approaches:
| Approach | Impact |
|---|---|
| Single Complex Prompt | Base accuracy, high resource usage |
| Decomposed Tasks | 2-5% higher accuracy, 30-40% less usage |
| Hybrid (Complex + Simple) | Mixed results, moderate resource use |
For instance, in recent testing, Llama-70B nearly matched GPT-4’s performance on the GSM8k dataset (94.6% vs. 95.4%) while requiring far fewer computational resources [1]. This shows how breaking tasks into smaller parts can keep performance high while reducing overhead.
Once tasks are broken down, it’s essential to fine-tune and adapt prompts to maintain their effectiveness in real-world scenarios.
3.2 Continuously Adjusting Prompts
Prompts need regular updates to stay reliable at scale. Continuous improvement ensures they perform consistently in dynamic environments.
To refine prompts in production:
- Monitor Key Metrics: Keep an eye on accuracy, response times, and error trends.
- Gather User Feedback: Use feedback to uncover weak spots and refine prompts.
- A/B Test Variations: Experiment with different versions to find the best-performing prompts.
For long-term success, focus on:
- Domain-Specific Knowledge: Tailor prompts to the specific field for better results.
- Performance Tracking: Leverage analytics to evaluate prompt effectiveness.
- Resource Efficiency: Strike a balance between model size and performance needs.
4. Advanced Techniques for Better Results
Improving LLM performance in production requires advanced strategies that focus on precision, consistency, and efficient resource management.
4.1 Using Few-Shot Prompting
Few-Shot Prompting boosts LLM accuracy by embedding a handful of examples directly into the prompt. This approach eliminates the need for retraining, making it ideal for production systems where modifying the model isn’t feasible.
Research shows that few-shot prompting can increase accuracy by 15-30%, offering a practical alternative to fine-tuning [4]. To get the most out of this method, select 2-3 well-crafted examples that clearly illustrate the desired input-output relationship. Consistent formatting across these examples helps guide the model more effectively.
4.2 Applying Chain-of-Thought Prompting
Chain-of-thought prompting enhances problem-solving by breaking tasks into logical steps, encouraging the model to follow a structured reasoning process [4]. This approach is particularly useful for handling complex problems and ensuring more reliable outputs [5].
For effective chain-of-thought prompting:
- Clearly outline each reasoning step.
- Regularly evaluate the quality of responses.
- Strike a balance between detailed reasoning and efficient processing.
Both techniques require ongoing evaluation and adjustments based on performance metrics and user feedback [6]. By carefully applying these methods, organizations can improve the reliability and effectiveness of their LLM systems without sacrificing operational efficiency.
These strategies set the stage for managing prompts in production environments, which we’ll cover next.
5. Managing Prompts in Production
Managing prompts effectively in production environments calls for a clear strategy that brings together organization, monitoring, and ongoing improvements. Scaling large language models (LLMs) depends heavily on having a strong system for prompt management.
5.1 Using Centralized Repositories
A centralized repository acts as the main hub for managing prompts across different teams and projects. This setup minimizes duplication and ensures prompt engineering remains consistent. By maintaining a central library, organizations can:
- Keep detailed documentation, including version history and performance data
- Share optimized templates across teams for better efficiency
- Apply uniform testing methods to maintain quality
Best Practice: Include metadata with each prompt, such as its purpose, performance stats, and revision history. This makes it easier for teams to quickly find and deploy the most effective prompts for specific tasks.
Centralized repositories don’t just streamline operations; they also make it easier to scale by enabling prompt reuse and collaborative efforts. Once this foundation is in place, the next priority is tracking performance to ensure prompts continue to deliver results.
5.2 Monitoring Performance
Monitoring is critical to ensure prompts perform well in production. It’s important to track both technical metrics and their impact on business outcomes.
| Metric Category | Key Indicators | Purpose |
|---|---|---|
| Technical Performance | Response accuracy, processing time, error rates | Improve system efficiency |
| Business Impact | User satisfaction, task completion rates, cost efficiency | Assess overall value |
| Resource Usage | Token consumption, API calls, computational load | Optimize resource use |
With these metrics in place, specialized tools can help simplify the process of managing and refining prompts.
5.3 Utilizing Latitude
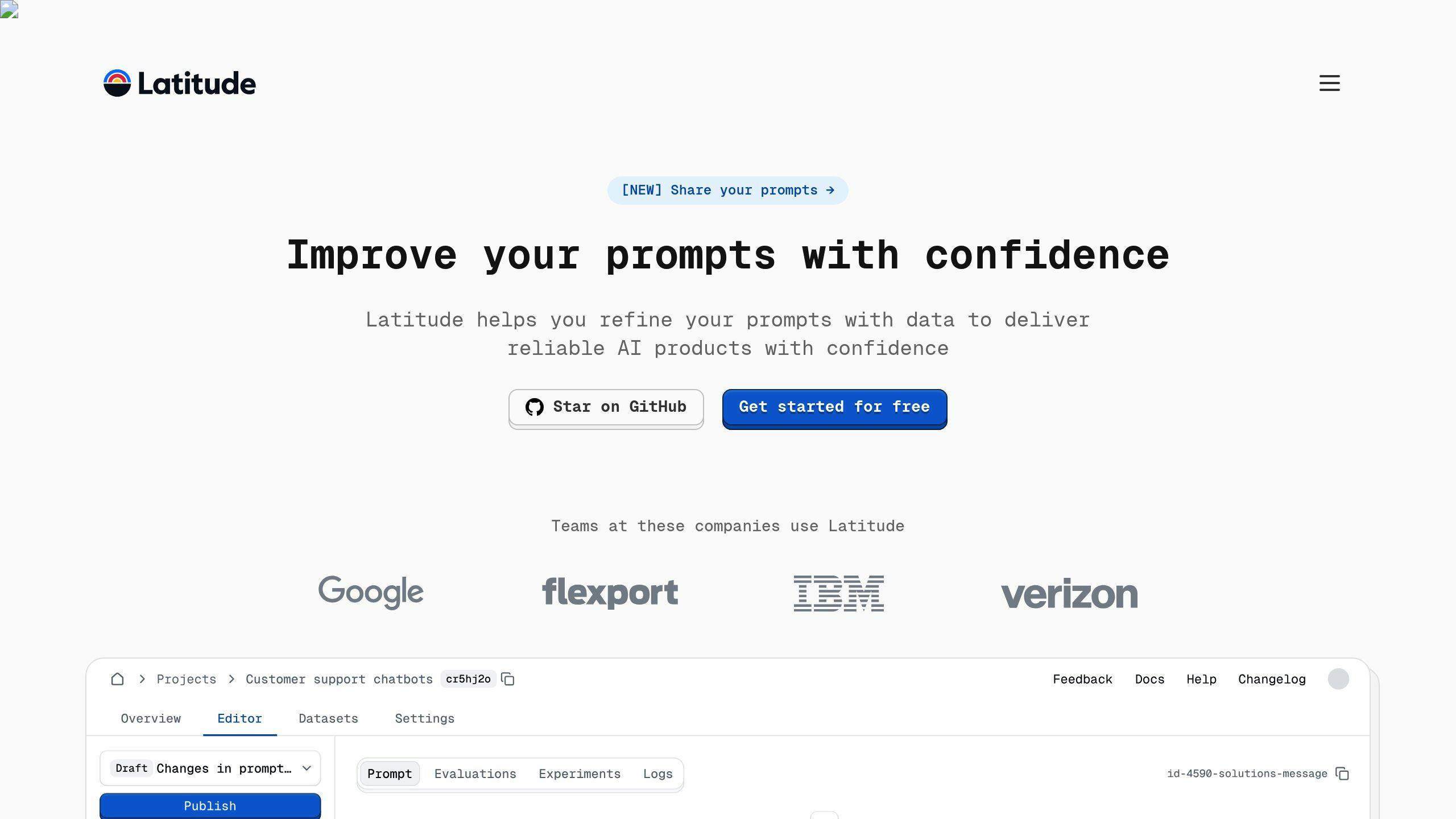
Latitude is an open-source platform tailored for managing prompts in production environments. It fosters collaboration between domain experts and engineers by offering features like:
- Version control for prompt libraries to track changes
- Built-in tools for collaborative testing
- Dashboards to monitor performance metrics
Latitude’s open-source framework allows teams to adapt and expand its features to suit their unique requirements, making it a flexible choice for improving prompt workflows.
Pro Tip: Schedule regular reviews of prompts in production. Use performance data to identify areas for improvement, ensuring high-quality results while keeping resource usage in check.
Conclusion: Key Strategies for LLM Prompt Optimization
With strong management systems in place, organizations can refine prompts to meet changing production needs. Optimizing prompts requires a clear and methodical approach that emphasizes precision, scalability, and advanced methods.
The key to effective optimization starts with clear implementation and ongoing refinement. Well-structured, focused prompts with specific language form the backbone of dependable production workflows. Pairing these with reusable templates creates a flexible framework that adjusts to shifting business requirements.
Advanced methods play a crucial role in improving prompt quality. Techniques like few-shot prompting help guide LLMs by showing examples of desired outputs, while chain-of-thought prompting breaks down complex reasoning into smaller, logical steps. These methods lead to better problem-solving and more accurate results [2].
| Optimization Layer | Key Components | Impact |
|---|---|---|
| Foundation | Clear instructions, structured formats | Consistent outputs |
| Scalability | Task decomposition, prompt updates | Better performance at scale |
| Advanced Methods | Few-shot, chain-of-thought prompting | Greater accuracy |
| Management | Centralized repositories, monitoring | Efficient operations |
Prompt tuning has become a practical alternative to traditional fine-tuning. It allows teams to use existing model parameters without the need for extensive retraining [3]. When paired with strong monitoring systems and tools like Latitude, this approach provides a reliable way to maintain and improve prompt performance over time.
FAQs
How to optimize LLM prompt?
Improving LLM prompts in production requires careful planning and ongoing adjustments. Below are some practical strategies to help you fine-tune prompts for better performance while keeping resource use in check.
Key Optimization Techniques:
-
Structure and Context
- Use clear, specific language tailored to your production goals.
- Incorporate external knowledge sources for added context.
- Break down complex tasks into smaller, easier-to-handle parts.
-
Technical Implementation
- Experiment with soft prompt tuning for more efficient adjustments.
- Leverage methods like few-shot learning and chain-of-thought prompting (see Section 4 for details).
- Balance optimization efforts with available resources to avoid overloading systems.
-
Testing and Monitoring
- Run A/B tests to evaluate different prompt variations.
- Measure key metrics like accuracy and user satisfaction to assess performance.
- Use feedback from the model itself to refine and improve prompts over time.
In production settings, consistent monitoring and adjustments are essential to ensure prompts stay effective as requirements evolve. These strategies, when applied thoughtfully, can help maintain strong performance while managing resources efficiently.